Hey there!
Welcome to ClearUrDoubt.com.
In this post, we will look at the WordCount program in Spark using Java 8.
Before going through the below program, it’s better to look into below concepts for a better understanding of the program:
- org.apache.spark.api.java.JavaRDD
- org.apache.spark.api.java.JavaPairRDD
- scala.Tuple2<T, U>()
- mapToPair() Transformation
Here is the pom.xml:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 |
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd"> <modelVersion>4.0.0</modelVersion> <groupId>com.sample</groupId> <artifactId>JavaWordCount</artifactId> <version>0.0.1-SNAPSHOT</version> <name>java_word_count</name> <dependencies> <!-- https://mvnrepository.com/artifact/org.apache.spark/spark-core --> <dependency> <groupId>org.apache.spark</groupId> <artifactId>spark-core_2.11</artifactId> <version>2.2.1</version> </dependency> <!-- https://mvnrepository.com/artifact/org.apache.hadoop/hadoop-hdfs --> <dependency> <groupId>org.apache.hadoop</groupId> <artifactId>hadoop-hdfs</artifactId> <version>2.9.1</version> </dependency> </dependencies> <properties> <maven.compiler.target>1.8</maven.compiler.target> <maven.compiler.source>1.8</maven.compiler.source> </properties> <build> <finalName>java_word_count</finalName> </build> </project> |
Here is the Java 8 program:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 |
package com.sample; import java.util.Arrays; import org.apache.spark.SparkConf; import org.apache.spark.api.java.JavaSparkContext; import org.apache.spark.api.java.JavaRDD; import org.apache.spark.api.java.JavaPairRDD; public class JavaWordCount { public static void main(String[] args) { SparkConf config = new SparkConf().setAppName("JavaWordCount"); JavaSparkContext sc = new JavaSparkContext(config); JavaRDD<String> lines = sc.textFile(args[0]); JavaRDD<String> words = lines.flatMap( line -> Arrays.asList(line.split(" ")).iterator()); JavaPairRDD<String, Integer> pairs = words.mapToPair( word -> new scala.Tuple2<String, Integer>(word, 1)); JavaPairRDD<String, Integer> counts = pairs.reduceByKey((a, b) -> a + b ); counts.saveAsTextFile(args[1]); sc.close(); } } |
Output:
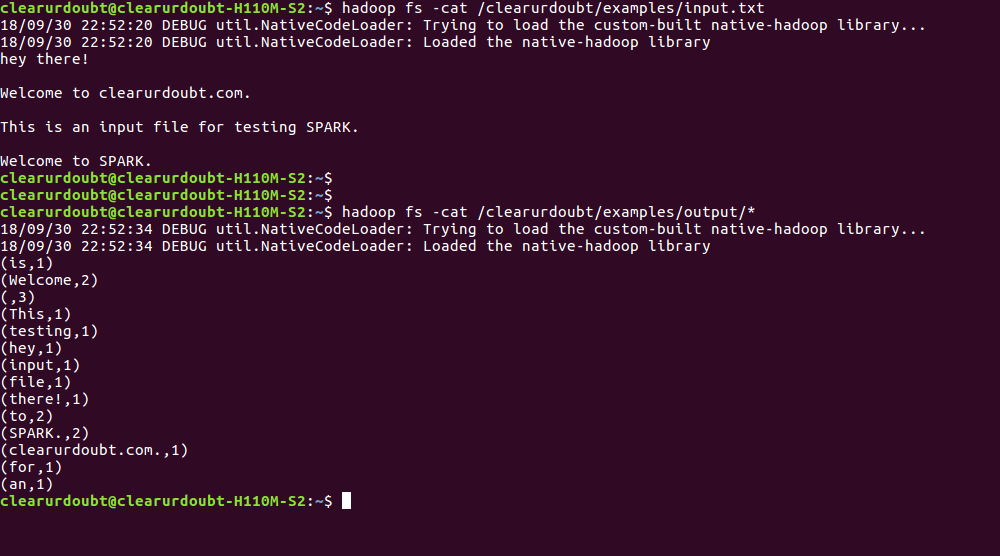
Happy Learning :).
Please leave a reply in case of any queries.