Hey there!
Welcome to ClearUrDoubt.com.
In this post, we will look at a Spark(2.3.0) Program to load a CSV file into a Dataset using Java 8.
Please go through the below post before going through this post.
Program to load a text file into a Dataset in Spark using Java 8
Consider a scenario where clients have provided feedback about the employees working under them. We need to find the top employee under each client based on the feedback.
Let’s create a sample program to create sample data:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 |
package com.sample; import java.io.BufferedWriter; import java.io.File; import java.io.FileWriter; import java.io.IOException; public class CreateSampleData { public static void main(String[] args) { createSampleData(); } private static void createSampleData() { BufferedWriter bw = null; try { //create a folder in LFS using the command: "mkdir -p /home/clearurdoubt/examples/" bw = new BufferedWriter(new FileWriter(new File("/home/clearurdoubt/examples/samplefeedback.csv"))); for(int i = 1, j = 1000; i <= 100000; i++, j++) { //employee_id, feedback1, feedback2, feedback3, feedback4, feedback5, client_id bw.write(String.format("%08d", i) + "," + (int)(Math.random() * 100) + "," + (int)(Math.random() * 100) + "," + (int)(Math.random() * 100) + "," + (int)(Math.random() * 100) + "," + (int)(Math.random() * 100) + "," + (j + 1)); bw.write("\n"); if(j >= 1999) { j = 1000; } } } catch(IOException ioe) { System.out.println("An IOException has been raised. " + ioe.getMessage()); ioe.printStackTrace(); } finally { try { System.out.println("Data Preparation is completed."); bw.close(); } catch(IOException e) { System.out.println("Unable to close the BufferedWriter object."); } } } } |
Sample file:
|
1 2 3 4 5 6 7 8 9 10 11 |
clearurdoubt@clearurdoubt-H110M-S2:~$ cat /home/clearurdoubt/examples/samplefeedback.csv | head -10 00000001,75,40,21,10,92,1001 00000002,29,30,80,98,10,1002 00000003,97,64,18,63,85,1003 00000004,78,59,3,0,81,1004 00000005,86,19,64,24,91,1005 00000006,35,80,45,53,86,1006 00000007,37,31,34,61,68,1007 00000008,97,8,67,40,14,1008 00000009,71,72,31,87,39,1009 00000010,50,0,56,0,26,1010 |
Let’s look at the pom.xml and Spark programs:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 |
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd"> <modelVersion>4.0.0</modelVersion> <groupId>com.sample</groupId> <artifactId>FeedbackAnalyzer</artifactId> <version>0.0.1-SNAPSHOT</version> <dependencies> <!-- https://mvnrepository.com/artifact/org.apache.spark/spark-core --> <dependency> <groupId>org.apache.spark</groupId> <artifactId>spark-core_2.11</artifactId> <version>2.3.0</version> </dependency> <!-- https://mvnrepository.com/artifact/org.apache.spark/spark-sql --> <dependency> <groupId>org.apache.spark</groupId> <artifactId>spark-sql_2.11</artifactId> <version>2.3.0</version> </dependency> <!-- https://mvnrepository.com/artifact/org.apache.hadoop/hadoop-hdfs --> <dependency> <groupId>org.apache.hadoop</groupId> <artifactId>hadoop-hdfs</artifactId> <version>2.8.5</version> </dependency> <dependency> <groupId>com.databricks</groupId> <artifactId>spark-csv_2.11</artifactId> <version>1.3.0</version> </dependency> </dependencies> <properties> <maven.compiler.target>1.8</maven.compiler.target> <maven.compiler.source>1.8</maven.compiler.source> </properties> <build> <finalName>feedback_analyzer</finalName> </build> </project> |
Spark program:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 |
package com.sample; import static org.apache.spark.sql.functions.col; import org.apache.spark.SparkConf; import org.apache.spark.sql.Dataset; import org.apache.spark.sql.Row; import org.apache.spark.sql.SaveMode; import org.apache.spark.sql.SparkSession; import org.apache.spark.sql.functions; import org.apache.spark.sql.expressions.Window; import org.apache.spark.sql.types.DataTypes; import org.apache.spark.sql.types.Metadata; import org.apache.spark.sql.types.StructField; import org.apache.spark.sql.types.StructType; public class FeedbackAnalyzer { public static void main(String[] args) { SparkConf conf = new SparkConf().setAppName("Feedback Analyzer"); SparkSession spark = SparkSession.builder().config(conf).getOrCreate(); // Define schema of the CSV file StructType schema = new StructType(new StructField[]{ new StructField("employee_id", DataTypes.StringType, false, Metadata.empty()), new StructField("feedback_response1", DataTypes.IntegerType, false, Metadata.empty()), new StructField("feedback_response2", DataTypes.IntegerType, false, Metadata.empty()), new StructField("feedback_response3", DataTypes.IntegerType, false, Metadata.empty()), new StructField("feedback_response4", DataTypes.IntegerType, false, Metadata.empty()), new StructField("feedback_response5", DataTypes.IntegerType, false, Metadata.empty()), new StructField("client_id", DataTypes.StringType, false, Metadata.empty()) }); //Read the CSV file to a DataSet Dataset<Row> df = spark.read().format("csv").option("header","true").schema(schema).option("mode","PERMISSIVE").load(args[0]); df.show(); //Add all the feedbacks of employees as final_feedback Dataset<Row> updated_df = df.select(df.col("employee_id"), df.col("client_id"), df.col("feedback_response1").plus(df.col("feedback_response2")) .plus(df.col("feedback_response3")) .plus(df.col("feedback_response4")) .plus(df.col("feedback_response5")).alias("final_feedback")  ); updated_df.show(); //Use the Window function Rank() to rank the feedbacks of emplyees Dataset<Row> ranked_df = updated_df.withColumn("rank", functions.rank().over(Window.partitionBy("client_id").orderBy(functions.desc("final_feedback")))); ranked_df.show(); //Consider only the top rated employees under each client Dataset<Row> final_df = ranked_df.select(col("client_id"), col("employee_id"), col("final_feedback").as("top_feedback")).where(col("rank").equalTo("1")).orderBy("client_id"); final_df.show(); //Write the DataSet to a csv file. final_df.coalesce(1).write().mode(SaveMode.Overwrite).csv(args[1]); } } |
Spark submit command:
|
1 |
clearurdoubt@clearurdoubt-H110M-S2:~$ spark-submit --class com.sample.FeedbackAnalyzer --master local --packages com.databricks:spark-csv_2.11:1.3.0 /home/clearurdoubt/workspace/FeedbackAnalyzer/target/feedback_analyzer.jar /user/clearurdoubt/examples/samplefeedback.csv /user/clearurdoubt/examples/output |
Output:
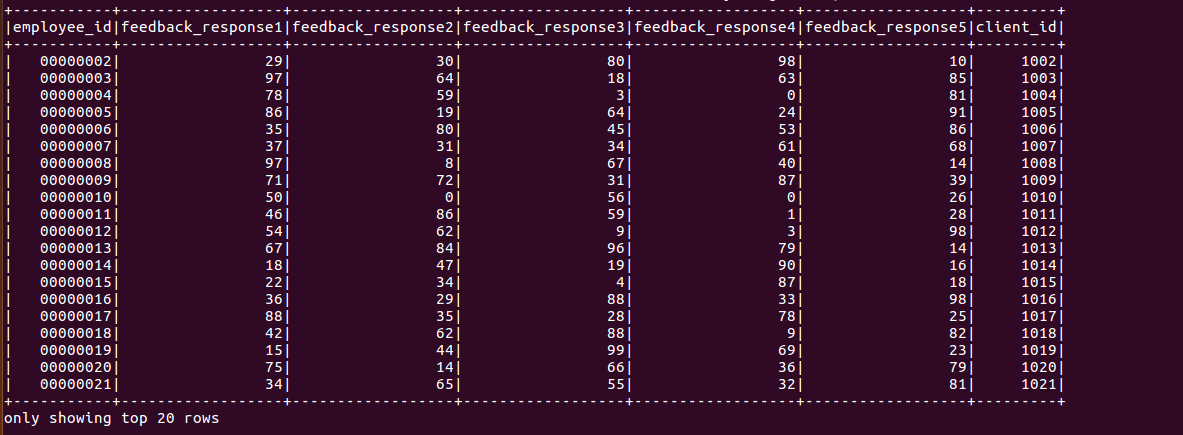
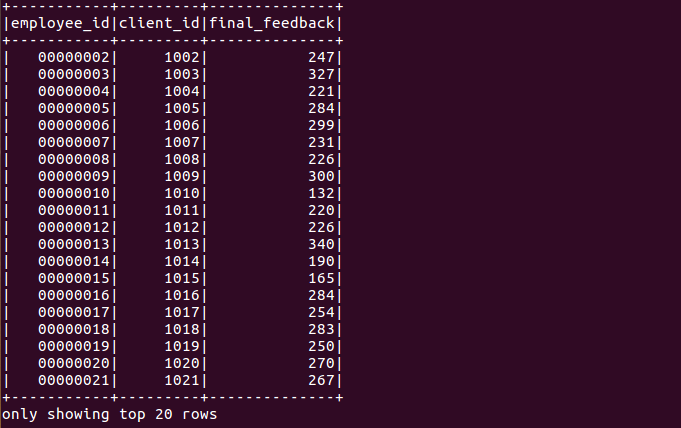


The output file will be saved in the file specified in the spark-submit command.
Happy Learning :).
Please leave a reply in case of any queries.
Thank you