Apache Spark is a fast and general-purpose cluster computing system. Spark supports in-memory processing for parallel computation which is why it is pretty much faster than a Map-Reduce process.
It supports a rich set of tools like
- Spark SQL – Structured Data Processing
- MLlib – Machine Learning
- GraphX – Graph processing
- Spark Streaming – real-time data processing
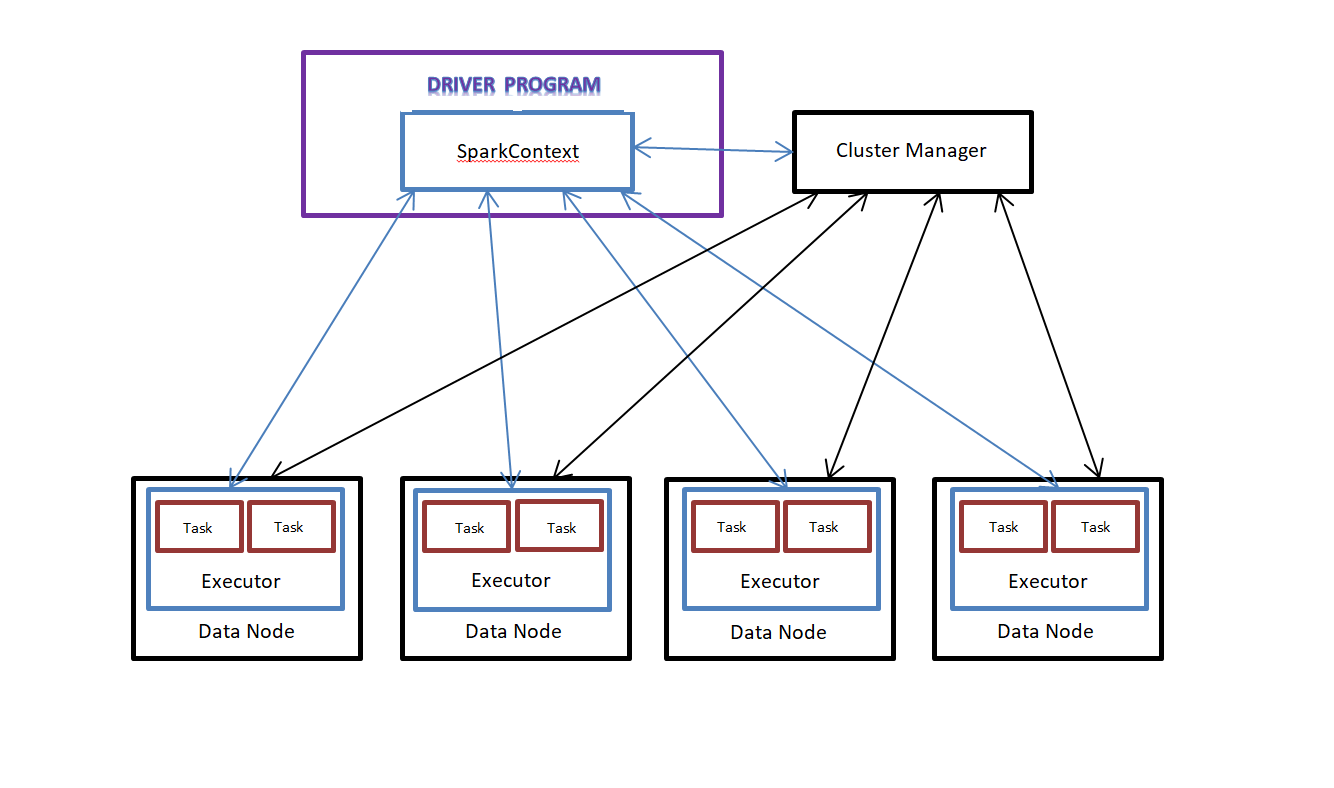
Running Spark Jobs on Cluster
> Driver Program – The main program which initializes the SparkContext and launches the parallel tasks
> SparkContext object – It works with the Cluster Manager and acts as a bridge between Driver program and the cluster.
> Cluster Manager – Manages the resource allocations to the corresponding Spark Applications.
> Executor – Process that runs on a data node in the cluster and responsible for performing the parallel tasks of Spark Applications.